 CVS
CVS
(Concurrent Version System)
1 Le Principe
2 Pour quoi faire ?
3 Les solutions
4 Comprendre
5 Configuration de la partie serveur
5.1 Installer le serveur
5.2 Utilisation en local sans accès distant
5.2.1 Placer dans le dépôt votre travail
5.2.2 Simplifiez vous la vie
5.2.3 Commencer à développer
5.3 Vous souhaitez pouvoir utiliser CVS depuis d'autres machines et permettre à d'autres de l'utiliser.
5.3.1 Vous devez d'abord configurer Inetd.conf ou xinetd.
5.3.2 Créer un utilisateur et se connecter.
5.3.3 Gérer les droits
5.3.4 Les fichiers de CVSROOT
6 Les commandes
6.1 Exemples des commandes les plus utilisées
6.2 Les options de la commande CVS
7 Cas particuliers
7.2 Renommer un fichier
7.3 Restaurer un fichier effacé
8 Messages
9 Les branches
10 Les clients Linux
11 Les clients Windows
11.1 wincvs
11.2 Tortoise
12 WebCVS
13 En savoir plus
CVS est un outil permettant à plusieurs personnes de travailler sur un projet commun, de développement, et pourquoi pas un projet de documentation. Vous disposez alors sur votre propre machine d'une copie de l'arborescence de développement, et lorsque vous le souhaitez vous pouvez proposer une mise à jour ou un développement nouveau après avoir rapatrié la dernière version depuis le serveur CVS. CVS gérera alors les différences et gardera un historique de l'ensemble du projet. En aucun cas vous ne pouvez effacer un fichier, vous pouvez aussi remonter à chaque version de votre développement, ainsi si vous constatez une mauvaise direction vous pouvez revenir à la version antérieure.
Dans le cadre éducatif
quel est le but d'un serveur CVS, et que peut on en faire ?
D'abord pour vous aider à développer des produits, et permettre
à d'autres de ne pas réinventer la roue à chaque fois.
Les projets communs sont souvent les plus complets et les mieux faits.
Par exemple, vous souhaitez développer en PHP la gestion des notes
ou la gestion des salles ou même un outil de travail collaboratif.
Le travail est important, il a plus de chance d'aboutir à plusieurs
que seul.
Ensuite pour permettre éventuellement aux élèves
des classes informatiques de voir un outils de travail qui exige une certaine
rigueur et permet de travailler sur un projet commun. N'est ce pas d'actualité...!?
Suivant la situation,
il vous faut le client (dans tous les cas) et éventuellement le serveur
(si vous souhaitez en avoir un pour vous même sur votre machine en
local).
Se pose encore à vous l'OS que vous utilisez :
Pour Linux ou BSD le client (en ligne de commande) a une forte chance
de se trouver déjà sur votre machine (tapez CVS pour voir).
Sinon on trouve les sources sur le CD de votre distribution, on trouve aussi
des clients graphiques, mais je ne les utilise pas. Pour la partie "serveur"
il n'existe pas vraiment des choses en plus, Il vous faut simplement utiliser
TCP_Wrappers ou SSH, si la machine est une machine distante, sinon (en local
sur votre propre machine) il vous faut simplement créer et initialiser
le dépôt.
Pour windows il existe plusieurs solutions clientes qui sont wincvs (le
plus complet) et un assez simple
tortoiseCVS
qui se place dans l'explorer. Il semble qu'il existe aussi un serveur
CVS pour NT, mais je ne le connais pas.
Enfin un outils bien pratique webcvs, permet de voir l'ensemble de votre
développement, de voir les modifications avec des différences
de couleurs. Cet outil étant une interface web, vous devez avoir
un serveur apache d'installé.
Avant de commencer il
vous faut comprendre le principe de fonctionnement.
Vous devez avoir un serveur sur lequel vous avez créé un
dépôt (repository). La première fois vous "envoyez"
votre premier développement qui se trouve en local sur votre machine
au serveur (import).
Puis vous devez faire un "checkout" pour redescendre la version qui se
trouve sur le serveur, sur votre machine, dans votre répertoire de
développement, vous allez alors avoir un répertoire CVS, qu'il
ne faut pas modifier. Ce répertoire est utilisé par cvs pour
comparer ce qui est sur le serveur et ce qui est sur votre machine.
Par la suite si vous êtes le seul à travailler sur le serveur
vous devez utiliser des "commit" pour faire les mises à jour, et
éventuellement des "add" pour ajouter des nouveaux fichiers, ou répertoires.
Par contre si vous êtes plusieurs à travailler sur votre
projet, cela demande un peu plus de rigueur, à savoir à chaque
fois que vous modifiez des choses sur le projet, vous devez d'abord vérifier
que quelqu'un n'est pas passé avant vous et que le fichier que vous
venez de modifier n'a pas déjà été modifié.
Par précaution faites un "co" ou "checkout" avant sinon vous risquez
d'avoir un problème que CVS vous indiquera au moment du "commit".
Enfin au moment ou vous pensez que votre développement est stable
vous le "taguez" de façon à pouvoir le retrouver par la suite
sous un nom plus parlant et surtout de pouvoir retrouver l'ensemble des scripts
correspondants à ce tag, même si par la suite l'ensemble du
projet continue à évoluer.
Vous pouvez par la suite retrouver les différentes versions de
chaque fichier de votre projet et de voir les différences apportées
"diff", "log", "status".
5 Configuration de la partie
serveur
Il n'y a pas grand chose
à faire.
- Créez le dépôt (repository), l'endroit ou CVS va
placer les sources et les mises à jour, par exemple dans le répertoire
/home on crée un répertoire cvs (
mkdir /home/cvs ).
CVS ne recrée pas de nouveaux fichiers à chaque mise à
jour, il crée seulement la différence, ce qui implique qu'il
n'a pas besoin d'un grand espace. Vous ne devez jamais intervenir dans ce
répertoire, autrement qu'avec le client CVS.
- Initialisez le dépôt
cvs -d /home/cvs init
(cela est fait une bonne fois pour toute).
- Voilà vous avez terminé. Dans le répertoire /home/cvs
vous avez un répertoire CVSROOT. Encore une fois vous ne devez jamais
intervenir dedans... j'ai bien dis JAMAIS.
- Pour éviter d'avoir à réécrire à
chaque fois -d /home/cvs céez une variable d'environnement, sur
votre machine cliente, pour indiquer à CVS ou se trouve le dépôt
export CVSROOT='/home/cvs'
.
Se pose à vous maintenant l'usage que vous allez faire de ce serveur.
Est-il pour vous seulement, sur votre propre machine sans accès distant
ou doit il être ouvert à d'autres.
5.2.1 Placer dans
le dépôt votre travail
- Copier dans le dépôt votre travail (Je suppose ici que
vous avez déjà créé des petites choses). Placer
vous dans le répertoire de développement local et faites (je
suppose ici que vous avez créé la variable d'environnement,
sinon ajouter -d /home/cvs) :
cvs import -m "Ma première
version" /home/cvs/mon_developpement moi version_1
- m "Ma première version" permet
d'indiquer un commentaire, si vous ne le faites pas ici CVS va ouvrir l'éditeur
VI (VI est utilisé par défaut mais vous pouvez spécifier
un autre éditeur avec la variable CVSEDITOR).
- /home/cvs/mon_developpement
est le nom de la branche de votre premier développement.
- moi
est le nom du fabricant, donc mettez le votre.
- version_1
la première version de votre développement (le premier tag).
5.2.2 Simplifiez vous la vie
- On peut ici donner un nom à son projet (module) de façon
à ne pas avoir à chaque fois à l'appeler avec son chemin
(répertoire). Pour cela il faut aller dans un répertoire quelconque
et faire un cvs checkout
CVSROOT. Vous allez alors copier sur "votre machine" le
répertoire "d'administration de CVS" (On utilise ici le sens votre
machine bien que vous travaillez déjà dessus pour différencier
la notion de serveur CVS et de client CVS). Vous avez alors les fichiers
de paramétrage de CVS dans votre répertoire temporaire. Dans
le fichier modules ajouter PHP /home/cvs/mon_developpement
sauvegardez.
Puis faire cvs commit
-m "Ajout du module PHP" PHP. Attention on ne peut pas
faire un commit en tant que root, il faut donc avoir donner les droits nécessaires
sur le répertoire à l'utilisateur qui "commit"....mais vous
ne travaillez jamais comme root sur votre machine..:)
L'avantage est que maintenant vous n'avez plus à donner le chemin,
mais simplement d'indiquer le nom du module, à savoir PHP (Pas une
bonne idée comme nom de module, car on a vite fait de développer
de nouvelles applications en PHP).
5.2.3 Commencer à développer
- A partir d'ici vous avez placé dans CVS votre première
version, mais bien sur, vous continuez à développer et vous
apporter des changements dans vos scripts, vous avez des nouveaux fichiers,
répertoires et vous devez en détruire.
- Vous devez d'abord recharger la version que vous venez de placer sur
CVS. Pour cela il vous faut aller dans un répertoire ou vous avez
l'habitude de développer puis faire
cvs checkout PHP (On peut aussi faire cvs co PHP) pour
récupérer les sources de votre développement. (Comprenez
moi bien, la première fois vous envoyez un nouveau projet dans le
dépôt de CVS, puis immédiatement vous devez le faire
redescendre sur votre machine afin de créer un répertoire CVS
sur votre machine locale dans le répertoire de travail, ceci afin
de permettre à CVS de gérer les différences entre votre
travail en local et le dépôt du serveur CVS).
- Faites vos modifications, ou même ajoutez des fichiers à
votre travail, lorsque vous pensez que cela est nécessaire vous allez
les placer dans le dépôt. Si le fichier existe déjà
un simple commit suffit.
cvs commit -m "Modification
de la couleur" table.php (ce fichier existe déjà
dans CVS). Ou si vous avez modifié beaucoup de fichiers
cvs commit - m "Modifications du jour" (CVS est capable
de trouver les fichiers modifiés en local).
Par contre si vous souhaitez ajouter un fichier qui n'existe pas faites
:
cvs add -m "Nouveau fichier
pour effacer" efface.php,
puis cvs commit -m
"fichier pour effacer" efface.php
- Détruire un fichier cela est plus compliqué, car on ne
peut jamais détruire un fichier dans CVS. Vous pouvez toujours faire
un remove (cvs remove fichier.php), mais ce fichier existera toujours sur
le serveur CVS....mais n'est ce pas le but de CVS (On peut le détruire
complètement mais cela n'est pas le but de cette documentation).
Attention pour faire un remove d'un fichier il faut que celui-ci n'existe
plus dans votre répertoire de travail, enfin pensez à faire
un commit.
Je vous laisse le soin de regarder l'ensemble des commandes pour voir
ce qu'il est possible de faire.
- A partir de là
vous avez l'ensemble de votre projet sur CVS. Ce qui compte maintenant pour
vous est comment je peux voir les différences entre mes mises à
jour, à quel moment une version de mon projet est stable. CVS gère
pour vous les numéros de versions. Tous les fichiers n'ont pas obligatoirement
un numéro de version identique, certains fichiers ont pu être
modifiés de nombreuses fois pas d'autres, hors CVS incrémente
à chaque commit votre numéro de version. Si à un moment
de votre développement vous considérez que votre travail est
stable vous pouvez le "taguer". Cela permettant de pouvoir retrouver l'ensemble
de fichiers correspondant à ce tag. Pour taguer
cvs tag stable_1. Ainsi par le suite vous pouvez retrouver
l'ensemble de vos fichiers par un simple
cvs co -r stable_1 PHP (si vous n'avez aucune version,
ou si vous souhaitez la placer dans un autre répertoire local) ou
cvs update -r PHP
si vous souhaitez écraser la version que vous avez.
5.3
Vous souhaitez pouvoir utiliser CVS depuis d'autres machines et permettre
à d'autres de l'utiliser.
Il y a plusieurs solutions pour faire cela, en utilisant rsh et pserver.
Je ne commente ici que pserver.
5.3.1
Vous devez d'abord configurer soit Inetd.conf, soit xinetd.
Cas de Inetd.conf
On suppose ici connu la notion de droits et de TCP_Wrappers sous Linux.
Vous devez placer dans le fichier /etc/inetd.conf la ligne suivante (si
elle n'est pas déjà là)
cvspserver stream tcp
nowait root /usr/bin/cvs cvs -f --allow-root=/home/cvs/mon_developpement/depot
pserver
Ne pas oublier ici de relancer inetd (ou simplement de le forcer à
relire son fichier killall -HUP inetd). Pensez aussi à vérifier
les fichiers hosts.allow et hosts.deny.
/usr/bin/cvs
indique l'endroit ou se trouve l'exécutable cvs.
--allow-root=/home/cvs
indique l'endroit ou se trouve le dépôt.
-f
permet de ne pas charger le fichier ~/.cvsrc (ce fichier permet de spécifier
des arguments aux commandes CVS sans être obligé de les saisir
à chaque fois).
Éventuellement il vous faut ajouter dans le fichier /etc/services
la ligne cvspserver 2401/tcp (je dis éventuellement parce qu'il
y a de fortes chances qu'il y soit déjà).
Si vous le souhaitez vous pouvez ajouter plusieurs lignes au fichier inetd.conf,
afin de gérer plusieurs dépôts.
Cas de xinetd
Créer le fichier : /etc/xinetd.d/cvspserver
service cvspserver
{
port = 2401
disable = no
socket_type = stream
protocol = tcp
wait = no
type = UNLISTED
user = root
group = cvs
env = HOME=/home/cvs
server = /usr/bin/cvs
server_args = --allow-root=/home/cvs -f pserver
}
Vérifier également
que la ligne suivante est bien présente dans le fichier services
: cvspserver 2401/tcp
Puis faites sous root : # /etc/init.d/xinetd restart
5.3.2
Créer un utilisateur et se connecter.
Il vous faut créer ici les logins pour permettre la connexion.
Pour cela j'utilise htpasswd du serveur Apache. Placez vous dans le répertoire
/home/cvs/CVSROOT et créez le fichier passwd (attention cela est
une exception, vous ne devez jamais créer directement dans ce répertoire
vous devez toujours passer par les commandes de CVS).
htpasswd -c passwd
nom_de_login. Il vous demande alors de donner un mot de
passe. Vous êtes ici dans le même cas que pour Apache, le fichier
passwd à des entrées de type
login:mot_de_passe_crypté. Pour ajouter d'autres
personnes faites la même commande sans
-c.
Pour accéder alors au serveur CVS la commande est
cvs -d :pserver:mon_login@cvs.ac-creteil.fr:/home/cvs login
Il vous demande alors le mot de passe qui vous a été
donné par l'administrateur du serveur CVS. Par la suite les commandes
sont identiques, sauf que vous devez donner la syntaxe un peu longue du
dessus par exemple pour un commit
cvs -d :pserver:mon_login@cvs.ac-creteil.fr:/home/cvs
commit -m "Pour l'exemple" index.php
Pour éviter cela vous devez ajouter une variable d'environnement
du type
export CVSROOT='pserver:mon_login@cvs.ac-creteil.fr:/home/cvs'
et cela sur la machine du réseau depuis laquelle vous vous connectez.
Vous n'avez plus qu'à faire un
cvs login. Je vous propose de mettre cette ligne directement
dans le fichier /etc/profile ...
A partir de là vous avez permis à d'autres de travailler
sur votre projet. Cela implique quelques règles, à savoir
vous n'êtes plus le seul à modifier votre projet, il vous faut
donc prendre soin de faire un update avant de retravailler dessus afin de
tenir compte des modifications apportées par les autres. Il se peut
toutefois qu'une nuit venue par un grand froid, vous décidiez de modifier
la même page. Au moment du premier "commit" il ne va pas y avoir de
problème, mais la deuxième personne qui va vouloir faire un
commit va avoir un problème. CVS est en mesure de traiter le problème,
ou alors de vous demander de le traiter à la main (en fait au téléphone
pour trouver un compromis entre les deux).
5.3.3
Gérer les droits
Jusque là on a considéré qu'il n'y avait qu'un
seul utilisateur. Cet utilisateur doit posséder un droit en lecture
écriture sur le dépôt (car cvs a besoin d'écrire
des locks).
Si vous avez à gérer plusieurs utilisateurs, il vous faut
créer un compte système par utilisateur (utilisez aussi les
groupes), ce qui n'est pas très pratique. On peut donc soit utiliser
des comptes linux, soit utiliser un mécanisme propre à CVS.
CVS offre une solution qui consiste à modifier le fichier passwd
avec VI par exemple, en transformant les lignes de la façon suivante
:
mon_login:mot_de_passe:compte_systeme
pour chaque compte que vous souhaitez créer. Vous n'avez alors
besoin que d'un compte système pour l'ensemble de vos comptes cvs.
Vous devez penser alors à donner les droits au compte "compte_systeme"
sur le dépôt. Vous devez donner à ce compte système
les droits : lecture, écriture et exécuter, car cvs à
besoin de créer des "lock" pour interdire l'accès simultané.
Cela pose un petit problème puisque tous les utilisateurs doivent
avoir un droit lecture écriture. Il existe une solution qui consiste
à déplacer hors du dépôt le "lock", vous devez
pour cela configurer le fichier config qui
se trouve dans CVSROOT.
Pour pouvoir ne donner que des droits de lecture, vous devez passer pas
pserver. Pour cela vous devez créer dans le dépôt (pas
directement mais en utilisant cvs) les fichiers readers ou/et writers, avec
dedans un "mon_login" par ligne.
CVS procède de la façon suivante :
Si l'utilisateur existe dans le fichier passwd et si son mot de passe
est correct, alors si le fichier
readers existe et si l'utilisateur est dedans il a un
accès en lecture seul, de même si le fichier
writers existe et qu'il n'est pas dedans il a toujours
un accès en lecture seul, si le fichier
writers existe avec l'utilisateur dedans il a alors le
droit lecture-écriture. Vous devez lire cela comme le plus restrictif
s'applique, donc si vous êtes dans
readers et dans
writers vous n'avez qu'un droit de lecture. Si aucun
des deux fichiers n'existent vous avez aussi un droit lecture - écriture.
Comment procéder
:
Commencer par rapatrier le répertoire CVSROOT en local
cvs -d /home/cvs co CVSROOT
Puis dans le répertoire rapatrié créer le fichier
writers touch writers
Ajouter l'utilisateur avec son nom de login cvs, dans ce fichier (Il doit
exister dans le fichier passwd)
puis ajouter le dans le dépôt
cvs add writers suivi d'un
cvs commit. Comme le fichier writers existe, seul l'utilisateur
se trouvant dedans pourra écrire dans le dépôt. Si vous
n'avez pas mis d'utilisateur alors personne ne pourra écrire.
Je ne traite pas ici la possibilité de déléguer le droit de créer des comptes sur le serveur CVS, par contre un besoin peut être de donner un droit anonymous afin de faire un checkout, il faut pour cela que la connexion soit sans mot de passe et en écriture seule. Ajouter le compte anonymous dans CVSROOT/passwd, puis ajouter un fichiers readers avec le nom (ou les noms) des utilisateurs anonymous qui n'ont que le droit de lecture.
Je propose ici une petite modification : En fait, il est effectivement intéressant d'avoir un compte système, mais dans ce cas pourquoi ne pas le faire pointer directement sur le répertoire de CVS ? Voilà ce qu'il faut faire pour que tout ça fonctionne correctement :
useradd
cvs -d /home/cvs
cd /home
chown -R cvs cvs
chmod -R 770 cvs
Après l'initialisation
du repository :
cd /home/cvs
chown -R cvs:cvs CVSROOT/
Le fichier passwd devient
:
mon_login:mot_de_passe:cvs
5.3.4 Les fichiers de CVSROOT
Le répertoire CVSROOT
qui se trouve dans le dépôt est créé avec la commande
init. En fait vous installez dans se répertoire un certain nombre
de fichiers qui sont utilisés pas CVS pour la configuration. Tous
les fichiers ne sont pas créés par l'initialisation. Il en
existe en plus que vous devez ajouter. Vous ne pouvez intervenir sur ces
fichiers qu'avec les commandes CVS (sauf pour le fichier passwd). Pour cela
faites un checkout du répertoire CVSROOT (cvs checkout CVSROOT) afin
de l'avoir en local, faites vos modifications puis faites un commit, afin
que cela soit pris en compte pas le serveur.
| checkoutlist | Liste des fichiers qui doivent se trouver dans le répertoire CVSROOT, mais qui n'y sont pas par défaut (exemple le fichier users). |
| commitinfo | Permet de lancer des commandes avant d'archiver un fichier
(avec un commit). La syntaxe dans le fichier est la suivante : nom_du_répertoire commande_à_exécuter |
| config | Permet de paramétrer certaines actions de CVS. LockDir indique l'endroit ou l'on stocke le fichier de lock. Cela évite en le changeant de place de donner des droits en écriture à tout le monde. PreservePermissions, n'est pas actif par défaut, cela ne fonctionne pas en mode client/serveur. Permet d'utiliser les fichiers particuliers. SystemAuth La valeur par défaut est yes, cela permet de valider l'utilisateur par le compte système, si l'utilisateur n'est pas présent dans le fichier passwd. TopLevelAdmin La valeur par défaut est yes. permet lorsque vous faites un checkout de placer le répertoire CVS au même niveau que le répertoire contenant le module. |
| cvsignore | Permet d'exclure certain type de fichiers listés
dans ce fichier, par exemple .back .old.... Il est possible dans ajouter. |
| cvswrappers | Permet de mettre en place des filtres pour les fichiers lorsqu'ils sont extraits (checkout, update) option -f, ou avant d'être archivés (commit ou import) option -t, ou permet de choisir la méthode de mise à jour : Merge ou Copie, par défaut la méthode est Merge (fusion) mais vous pouvez vouloir faire cela vous même en gardant une copie des deus versions, option -m "COPY" |
| editinfo | Permet d'indiquer l'éditeur de texte utilisé. Cela pouvant être paramétré suivant le répertoire. La syntaxe est nom_du_répertoire editeur_a_utiliser |
| history | Contient l'archivage des commandes checkout, commit, export, release, rtag et update. |
| loginfo | Permet d'executer un certain nombre d'actions après
une commit Par exmple pour envoyer un messages CVSROOT /usr/bin/mail -s "$s" moi@ac-creteil.fr |
| modules | Permet de donner des noms symboliques aux différentes hiérarchies de votre développement. Ainsi vous pouvez indiquer un alias, un chemin (l'utilisateur arrive alors directement au sous répertoire), une union entre plusieurs répertoires, permettant de les extraire d'un coup. On peut aussi indiquer des options, permettant de lancer des commandes. |
| notify | Permet d'envoyer des messages lorsque est réalisé un add, edit ou watch |
| passwd | Fichier à ajouter avec htpasswd par exemple
et qui contient la liste des utilisateurs de CVS. Le seul fichier
que l'on doit ajouter directement dans le répertoire. La syntaxe est Nom_de_connexion_cvs:mot_de_passe_crypté:compte_donnant_les_droits |
| rcsinfo | Le fichier "rcsinfo" est utilisé pour indiquer les fichiers à insérer dans l'éditeur lorsque celui-ci est invoqué lors d'un commit ou d'un import. |
| readers | Permet d'indiquer les personnes qui ne possèdent qu'un droit de lire dans le dépôt. L'utilisateur doit exister dans le fichier passwd. |
| taginfo | Permet de lancer un script pour vérifier la syntaxe du nom utilisé pour le tag |
| users | Ce fichier n'est pas créé à l'initialisation du dépôt. Il permet d'associer un E-mail à un nom de connexion. La syntaxe est login:E-mail |
| val-tags | Fichier utilisé par CVS, non modifiable. |
| verifymsg | Permet de lancer un script de vérification des commentaires passés avec des commit |
| writers | Permet d'indiquer les utilisateurs qui ont un droit en écriture. Ce fichier est à utiliser avec le fichier readers |
6
Les commandes
6.1
Exemples des commandes les plus utilisées
- Si vous n'avez pas créé une variable d'environnement
pour CVSROOT, pensez à ajouter -d /home/cvs (votre dépôt)
ou -d :pserver:login@serveur_cvs.fr:/home/cvs
|
Se loguer - déloguer |
|
|
cvs login |
Pour ce loguer sur le serveur cvs |
|
cvs logout |
Pour ce déloguer |
|
Initialiser le dépôt |
|
|
cvs init |
Pour initialiser le dépôt la première fois. Cette commande ne se fait qu'une fois, et doit être faites sur la machine qui gère le dépôt. |
|
Ajouter un nouveau projet |
|
|
cvs import -m "un nouveau travail" mon_projet fabriquant nom_du_tag |
Cette commande permet d'ajouter un nouveau projet en important un répertoire complet, mon_projet est le nom du module qui est pour le moment le répertoire, le fabriquant est plus flou, indiquer donc votre nom, et nom du tag est le premier tag qui vous permet de retrouver cette version à tout moment, même après les évolutions. |
|
Ajouter, supprimer un fichier - répertoire |
|
|
cvs add nouveau.php |
Cette commande permet d'ajouter un fichier ou un répertoire. Vous devez obligatoirement faire un commit après un add. Si vous n'ajoutez pas un -m "commentaire" vous allez lancer VI. |
|
cvs add -m "Commentaire" nouveau.php |
Idem avec le commentaire. |
|
cvs add un_repertoire |
Ajoute un répertoire, il faut faire un commit après |
|
cvs add -kb mon_fichier |
Permet d'ajouter un fichier dans le dépôt, sans que celui-ci soit pris en compte (historicisable) par cvs. |
|
cvs remove detruire.php |
Pour enlever un fichier de votre "repository" ou dépôt. Ce fichier n'est jamais enlevé complètement il peut être rappelé à tout moment. Vous devez faire un commit pour que cela soit effectif. |
|
Commit |
|
|
cvs commit |
Cette commande permet de soumettre une modification.
Comme cela elle "commit" l'ensemble des fichiers se trouvant sur votre
machine, et vérifie qu'il n'y a pas de conflit avec la version se
trouvant sur le serveur. |
|
cvs commit index.php |
Vous ne soumettez que le fichier index.php (il ouvre VI pour permettre l'ajout d'un commentaire). |
|
cvs commit -m "Mise à jour d'index.php le 10 Juillet 2001" index.php |
Vous soumettez le fichier index.php, en donnant un commentaire, vi ne sera alors pas lancer (il faut que le commentaire ne dépasse pas une ligne sinon vous devez utiliser vi). |
|
cvs commit -r 2.12 index.php |
Pour forcer un numéro de version. Il doit obligatoirement supérieur au numéro existant. |
|
Rapatrier des fichiers depuis le dépôt |
|
|
cvs checkout nom_du_module |
Pour récupérer en local l'ensemble du module "nom_du_module". Cela permet de créer le répertoire CVS sur votre espace de travail en local. Il est indispensable de le faire la première fois après un import. |
|
cvs checkout -r stable_1 nom_du_module |
Pour récupérer la version stable_1 du projet. Vous ne devez avoir aucune version sur votre machine ou alors vous devez l'avoir détruite. |
|
cvs update nom_du_module |
Pour mettre à jour en local ce qui se trouve sur le serveur lorsqu'il est utilisé par d'autres. Vous avez déjà une version du projet sur votre machine. |
|
cvs update -r stable_1 |
Pour mettre à jour à partir de la version stable_1 qui a été "taguer" avec le nom stable_1. Vous possédez déjà un répertoire de travail sur votre machine. |
|
cvs export -r stable_1 nom_module |
Commande identique à checkout, mais permet
de rapatrier sur son disque dans un répertoire autre que votre répertoire
de travail sans le répertoire CVS. Avec les options -R (le tag)
-d (la date) et le nom du module. |
|
Taguer |
|
|
cvs
tag stable_2 |
Lorsque vous considérez que votre travail
est stable ou mérite une attention particulière vous pouvez
le "taguer" en lui donnant un nom. |
|
cvs tag -d stable_1 mon_fichier |
Supprime un tag sur le fichier mon_fichier. On peut supprimer un tag sur un ensemble de fichier |
|
Voir ce qui a été fait |
|
|
cvs log |
Indique les logs sur les révisions, certaines options sont disponibles comme la date, le nom d'un fichier.... |
|
cvs log -wtoto -d ">01/11/2001" |
Affiche toutes les révisions depuis le 11 Janvier 2001 faites par l'utilisateur toto. |
|
cvs status |
Permet de connaître l'état d'un fichier. Vous pouvez savoir si votre fichier en local est à jour par rapport au dépôt. |
|
cvs diff mon_fichier |
Liste la différence entre la version local de "mon_fichier" et la version se trouvant sur le dépôt |
|
cvs diff -r 1.1 -r 1.4 mon_fichier |
Liste les différences entre deux révisions de "mon_fichier". |
|
cvs anotate mon_fichier |
Produit une vision chronologique des révisions |
|
cvs history |
Permet de voir l'historique des modifications |
|
cvs history -a -xM '-D 3 days ago' |
Permet de voir l'ensemble des fichiers modifiés depuis 3 jours. |
6.2 Les options de la commande CVS
La commande CVS dispose d'options dont la plus utilisée est -d afin d'indiquer le chemin du dépôt. Elles se placent entre CVS et la commande (add, commit, ...etc).
| -a | Permet de mettre en place pour le mode client serveur l'authentification. |
| -b <chemin> | Cherche les commandes RCS dans <chemin> |
| -d <chemin du dépôt> | Indique le chemin du dépôt. Peut être remplacé par la variable d'environnement $CVSROOT |
| -e <Edituer> | Indique l'éditeur à utiliser (VI par défaut) |
| -f | Permet de ne pas utiliser le fichier ~/.cvsrc. Cette option peut être donnée dans le fichier inetd.conf. cvsrc permet d'indiquer les options que l'on souhaite passer à chaque commande CVS effectuée. |
| -H | Donne l'aide d'une sous commande |
| -l | Désactive l'historique |
| -n | Permet de passer des commandes sans quelles ne s'appliquent. |
| -q | Presque pas de bruit |
| -Q | Pas de bruit |
| -r | Permet de n'avoir que les fichiers en lecture seul |
| -s VAR=<Variable> | Indique la variable utilisateur VAR |
| -T <Répertoire> | Indique le répertoire temporaire |
| -t | Affiche une trace de l'exécution d'un programme |
| -v | Affiche la version du fichier |
| -w | Permet d'extraire les fichiers en lecture écriture. Cette option est l'option par défaut. |
| -x | Permet de chiffrer les données |
| -z <1 à 9> | Indique le niveau de compression |
7
Cas particuliers
7.1
Effacer un répertoire
Pour supprimer un répertoire, il faut commencer par le supprimer
du répertoire local (
rm répertoire), puis le supprimer dans le dépôt
( cvs release -r répertoire
) et enfin le supprimer sur les répertoires de tous les utilisateurs
( cvs update -P
).
7.2
Renommer un fichier
Cela n'est pas vraiment prévu sous cvs. La solution possible
est de le renommer en local (
mv mon_fichier new_mon_fichier), puis de le supprimer
dans le dépôt (
cvs remove mon_fichier), de remettre le nouveau (
cvs add new_mon_fichier), puis un commit (
cvs commit -m "nouveau nom" new_mon_fichier).
7.3
Restaurer un fichier effacé
On récupère en local la dernière version du
fichier ( cvs update
-r 1.1 mon_fichier_efface), puis on ajoute au dépôt
(cvs add mon_fichier_efface
), puis un commit (
cvs commit -m "le revoilà" mon_fichier_efface).
8 Messages
Lorsque
vous ajoutez un fichier, ou que vous faites un Checkout vous avez des messages
|
U Nom_du_fichier |
Updates |
Récupération de la dernière version du fichier. |
|
P Nom_du_fichier |
Patched |
Mise à jour de la dernière version du fichier |
|
M Nom_du_fichier |
Modified |
Vous avez modifiez le fichier |
|
C Nom_du_fichier |
Conflict |
Le fichier a déjà été commité. |
|
T Nom_du_fichier |
Tagged |
Le fichier vient d'être tagué |
|
? Nom_du_fichier |
Unknown |
Le fichier est inconnu |
9 Les branches
Le principe est assez simple, vous avez développé un programme
et vous l'avez fait évoluer dans une version 1.xx.. Problème
vous avez passé votre développement à votre voisin
qui refuse de faire une mise à jour. L'évolution que vous avez
fait prendre à votre développement demande plus de mémoire
et il refuse d'en remettre dans sa machine, en plus les options que vous
avez ajouté ne lui servent pas. Et oh malheur, il découvre
un bug. Vous devez alors revenir en arrière pour modifier cette ancienne
version. Vous devez donc à partir de la version qu'il a entre les
mains développer un correctif. Voilà rapidement exposé
le problème. Les branches permettent de faire évoluer le produit
en parallèle sur les deux versions.
Comment procéder :
On crée une nouvelle branche à partir de la version dont
le tag est version_1
cvs rtag -b -r version_1 version_1_1
On récupère cette branche
cvs update -r version_1_1 , on peut alors faire les modifications
pour corriger le bug.
On fait les modifications nécessaires et on commit la mise à
jour : cvs commit -m
"Anciennes modifs"
On revient à la version en cours :
cvs update -A
On peut maintenant constater que cette mise à jour est
aussi nécessaire pour la version sur laquelle on travaille, il faut
alors appliquer cette modification en tenant compte que depuis la version_1
votre projet à évoluer, il faut donc faire
cvs update -j version_1_1 mon_fichier
10 Les clients Linux
En plus de la ligne de commande qui me semble déjà bien pratique, sauf peut être pour voir les différences, mais alors on peut utiliser WebCVS, il existe une interface graphique sous KDE ou Gnome mais je ne connais pas bien. Vous essayez et vous me dites.
11
Les clients Windows
11.1
wincvs
Et oui depuis quelques temps on trouve des clients (gratuits) pour les
"windowseuries". Parmi les produits existants, le plus complet est WinCVS
( http://www.cvsgui.org
). Pour le configurer aller dans "admin" puis "préférences"
vous avez alors la fenêtre suivante qui s'ouvre. Il vous faut la remplir.
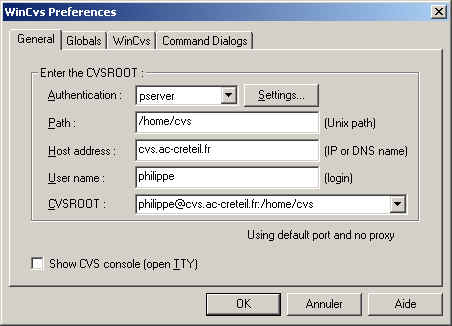
Puis toujours dans "admin" >> "login" pour vous connecter au serveur, il vous demande alors le mot de passe. J'ai eu des problèmes pour utiliser cette méthode, par contre en passant par la ligne de commande aucun problème. Cet outil est très complet, peut être trop.
11.2
Tortoise
Un autre produit (qui a ma préférence sous Windows) plus
simple mais suffisant pour passer toutes les commandes dont on a besoin
( http://www.cvsgui.org/TortoiseCVS/index.html
). Il s'intègre à l'explorer et se place dans le menu du
click droit de votre souris. Il ne pose pas de problème à
installer, mais par contre il est plus délicat à désinstaller,
cela n'étant pas prévu. Suivant l'endroit, sur un fichier,
un répertoire, sur un nouveau fichier ou un fichier déjà
ajouté, le menu s'enrichi de nouvelles commandes.
Vous devez commencer à le configurer pour indiquer le serveur,
le chemin du dépôt, le nom du module (attention ne nommé
pas le répertoire local dans lequel vous allez travailler CVS, ce
nom étant réservé). Aller pour cela dans Make New Module..
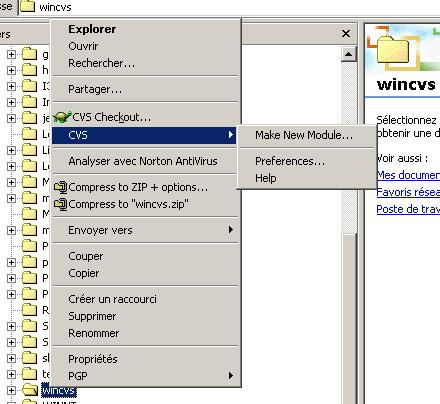
Vous obtenez alors, la boite suivante :
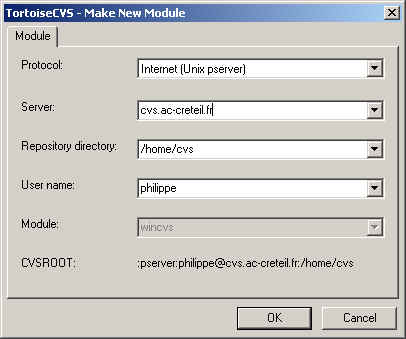
Une fois la configuration faite, vous pouvez faire un checkout pour rapatrier le module sur lequel vous souhaitez travailler. Vous obtenez une fenêtre presque identique avec en plus un onglet "Revision" qui vous permet de faire un checkout par nom de tag, branche, date.
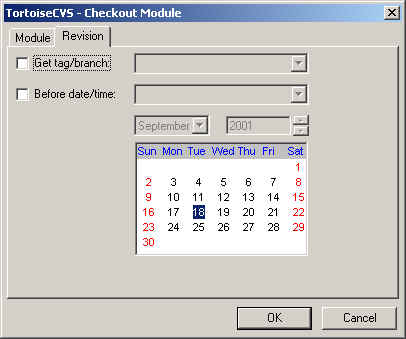
Dans le répertoire que vous venez de rapatriez, si vous cliquez droit dessus vous allez avoir un nouveau menu permettant de faire des commit, tag, branche, update. Attention vous devez avoir dans ce répertoire un répertoire au nom de CVS à ne pas toucher.
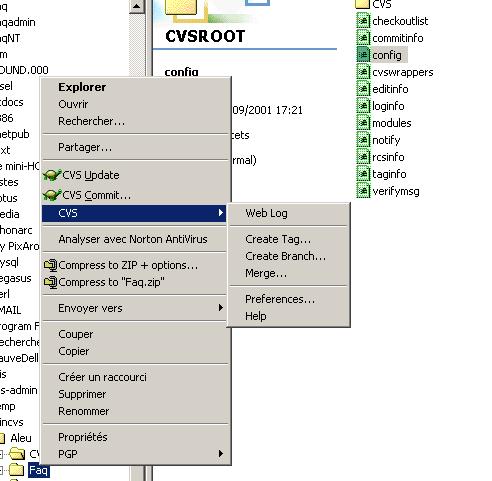
WebLog vous permet de voir les logs, mais tortoise utilise ici WebCVS, vous devez donc lui indiquer ou se trouve l'interface WebCVS si elle existe. Merge vous permet de faire une fusion de deux répertoires ou fichiers. Cet outil est vraiment bien et suffisamment complet pour faire l'essentiel côté client.
12 WebCVS
Un cgi qui vous permet
de voir l'ensemble de votre dépôt via une interface web. Vous
pouvez voir les fichiers et leur différences avec un jeu de couleur.
On ne peut pas faire des mises à jour avec cet outil, mais cela permet
de rendre vos développements visibles à d'autres.
Vous pouvez vous le procurer à http://www.spaghetti-code.de/software/linux/cvsweb
on le trouve aussi sous forme de RPM.
Pour qu'il fonctionne vous devez avoir Apache, PERL, ainsi que rlog et
rcsdiff d'installés sur votre machine. Pour le configurer vous devez
dans cvsweb.cgi indiquer ou vous avez placé le fichier cvsweb.conf,
puis dans cvsweb.conf indiquer ou se trouve le dépôt de cvs
sur votre machine. Il y a d'autres petites choses à changer pour adapter
l'interface et surtout penser à donner les bons droits. Il faut que
cvsweb.cgi puisse lire le dépôt donc avoir les droits nécessaires.
Pour voir le résultat je vous propose
http://cvs.ac-grenoble.fr
le serveur cvs de l'équipe de développement de SLIS.
13 En savoir plus
Vous trouverez sur les sites suivants un complément sur CVS. Cette documentation est loin d'en faire le tour.
www.cvshome.org
www.loria.fr/~molli/cvs-index.html
http://ganymede.ac-grenoble.fr/slis/devel/cvs-howto.html
© Philippe Chadefaux - 10/07/2001 - © Bruno Guégan (pour les rajouts xinetd ...) - 25/03/2002 -